OCR = Optical Character Recognition = Optische Zeichenerkennung (automatisch, computergestützt)
 |
Trathnigg, Gilbert (1963). „Das Handwerksbuch der Bader und Wundärzte der Viertellade Wels 1639 bis 1689“. In: Jahrbuch des Oberösterreichischen Musealvereines. Linz. https://www.zobodat.at/pdf/JOM_108_0210-0218.pdf |
Das funktioniert gut mit gedrucktem Text und einigermaßen gut mit maschinengeschriebenen Text, obwohl man bereits hier z.B. Zahlen wie Jahreszahlen und Seitennummern besonders gut prüfen muss.
 |
| Feichtinger, Ida (1969). Siedlungsgeschichte Ebensees - Die vier Grundobrigkeiten Ebensees als politische Verwaltungs-, Steuer- und Gerichtsbehörden. Selbstverlag: Mitterweißenbach. Maschinengeschrieben. |
Es funktioniert besser mit Wörtern, weil auch mit klassischer OCR Wörterbücher verwendet werden, um Wörter besser "erraten" zu können. Das geht aber natürlich nicht mit Zahlen.
Deshalb und wegen sprachspezifischen Sonderzeichen gibt man bei OCR die Sprache an.
Dass OCR auch bei der Frakturschrift funktioniert, sieht man z.B. bei ANNO-Zeitungen. Aber hier passieren schon viel mehr Falsch-Erkennungen.
 |
| ANNO Zeitungen, Ischler Wochenblatt, 1883, No. 10, 11. März 1883, Seite 4, https://anno.onb.ac.at/cgi-content/anno?aid=isl&datum=18830311&query=gigl&seite=4 |
Viele handgeschriebene, kursive (Schreibschrift-) Texte werden auch schon erkannt, wie man z.B. bei der vor kurzem freigegebenen Volkszählung 1950 in den USA sieht. Bereits vor der Freigabe haben die US-Volkszählungsbehörde, FamilySearch, Ancestry usw. Zeichenerkennungsprogramme drüber laufen lassen. Hier sind aber natürlich auch viele händische Nachkorrekturen notwendig.
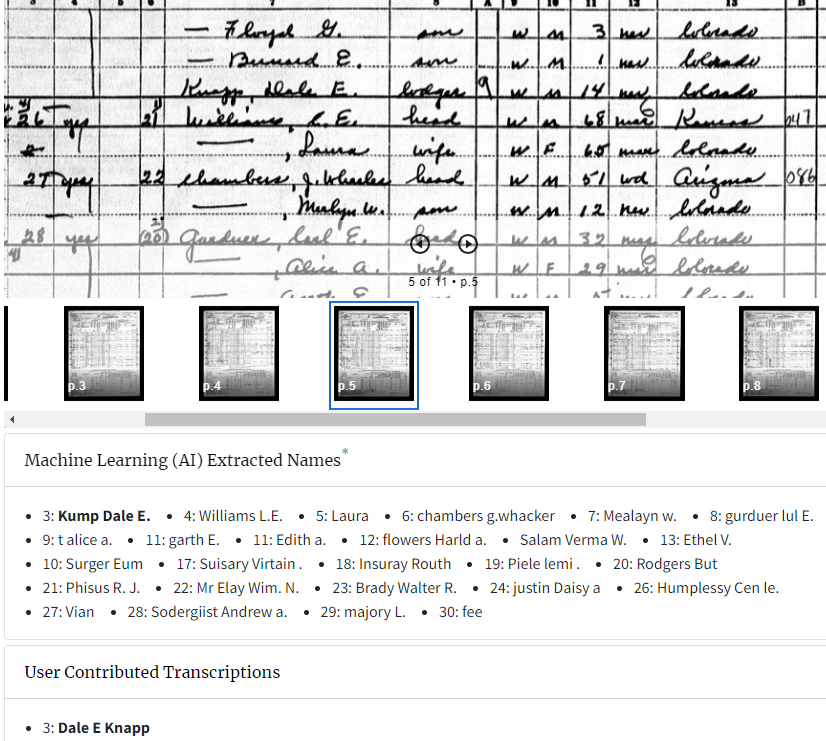 |
| Official 1950 Census Website, https://1950census.archives.gov/search/?name=dale%20e%20knapp&page=1 |
Der nächste logische Schritt ist die automatische Erkennung von (alten) in Kurrent geschriebenen Texten.
Das macht Transkribus.
- Transkribus entstand im Rahmen der EU-Projekte tranScriptorium (2013–2015) und READ (Recognition and Enrichment of Archival Documents, 2016–2019),
- wurde von der Universität Innsbruck bzw. der Gruppe Digitalisierung und elektronische Archivierung entwickelt,
- wird seither von der Europäischen Genossenschaft READ-COOP betrieben und weiterentwickelt, und
- verwendet Künstliche Intelligenz (= KI = Artificial Intelligence = AI) um handgeschriebenen Text in digitalen Text umzuwandeln (= zu transkribieren)
- Nochmals Sprache oben rechts wo „EN“ steht auf „DE“ ändern.
→ https://app.transkribus.eu/de - Technisch eine neue Website → wieder anmelden
- Oben rechts auf dem Männchen drüber fahren, unter „Language“ die Sprache wieder auf „DE“ ändern. → https://app.transkribus.eu/de/home (Diese Seite eventuell zu den Favoriten/Lesezeichen hinzufügen. Dann muss man nicht jedesmal die Sprache umstellen.)
- Hier wird der so genannte Workdesk angezeigt. Hierher kann man immer wieder zurückkehren, indem man links oben auf "Transkribus" klickt.
- Oben sind die zuletzt bearbeiteten Dokumente.
- Dann die Sammlungen. Ich habe derzeit nur eine Sammlung. Mehrere Benutzer können gleichzeitig in einer Sammlung arbeiten. Eine neue Sammlung kann man erstellen indem man im Menü links auf „Sammlung erstellen“ klickt.
- Darunter sind die neuesten Jobs. Man sieht, es gibt hauptsächlich 3 Arten von Jobs, das Heraufladen eines Dokuments („Create Document“), die Layout-Erkennung ("Layout analysis") und die Transkription (“Text-Erkennung“).
- Rechts Creditsaldo.
Anzahl teilbare Credits = 0 weil sie noch gratis sind. Gekaufte Credits kann man teilen.
Anzahl nicht teilbare Credits z.B. 482 heißt, dass man bisher 18 handgeschriebene Seiten transkribiert hat.
Anzahl handschriftliche bzw. gedruckte Seiten, die man mit den verfügbaren Credits transkribieren kann. - Klick auf eine Sammlung.
- Symbol "Ansicht wechseln" wechselt zwischen Miniaturansichten und Liste.
- In der Listenansicht kann man umsortieren.
- Es gibt mehrere Möglichkeiten ein Dokument hochzuladen.
Zum Beispiel über das Menü links oder am Workdesk rechts oben unter "Schnelles Erkennen von Text". Beim Menüpunkt "Text-Erkennung" hat man zwar weniger Schritte, aber man kann das Modell nicht auswählen. - Ich klicke meistens im Menü links auf "Hochladen". In meinem Fall ist die einzige Sammlung vorausgewählt.
- "Bild" oder "PDF" wählen. Man kann mehrere Dateien gleichzeitig hochladen. Bei PDF verbraucht man so viele Credits wie Seiten im PDF (handgeschrieben).
- Der Titel des Dokuments in Transkribus wird aus dem Dateinamen übernommen. Man kann aber auch später den Titel ändern.
- Man kann die Datei mit der Maus hinziehen oder auf "Browse" klicken und die Datei auf der Festplatte suchen.
- "Senden" klicken.
- "Jobs" klicken.
- Der neueste Job ist die soeben hochgeladene Datei.
- In der Spalte "Action" den Link klicken. Man kommt zum (eventuell mehrseitigen) Dokument.
- Falls der Dokument-Name nicht passt wieder zum Workdesk kehren, die Sammlung wählen, und auf dem "'i"-Symbol in der Miniaturansicht klicken. Titel ändern und eventuell weitere Angaben ändern.
- Man kann zwar die Layout-Erkennung und Text-Erkennung in einem Schritt machen. Ich mache das aber lieber in 2 Schritten, damit ich das Layout vor der Text-Erkennung anpassen kann.
- Eine Seite mit Klick auf das Kästchen links unten auswählen.
- Im Menü links auf "Layout-Erkennung" klicken.
- "Preset Model" und dann "Start" klicken. Nochmals "Start" klicken. Die beiden Fenster schließen.
- Im Menü links auf "Jobs" klicken.
- Wenn der oberste Job ("Layout analysis") fertig ist, in der Spalte "Action" auf den Link klicken.
- Auf der Miniaturansicht der Seite klicken.
- Unter dem Layout-Symbol kann man Regionen und Zeilen sortieren.
- Unter dem Info-Symbol steht, wie man Zeilen und Regionen trennen und zusammenfügen kann.
- Mit Rechtsklick auf der Maus kann man auch Objekte trennen usw.
- Auf das Diskettensymbol klicken, um zu speichern. Daneben steht Datum und Uhrzeit der letzten Speicherung. Man sollte immer wieder zwischendurch speichern, auch bei der Textbearbeitung.
- Wenn das Layout passt, dann auf das Symbol für Texterkennung klicken.
- Modell wählen. Hier wird zuerst immer „Transkribus Dutch Handwriting M2“ vorgeschlagen. Dies funktioniert meiner Erfahrung nach nicht sehr gut. Ist ja auch Holländisch.
- Die Sprache kann man auf Deutsch eingrenzen. "deu" unter Sprache eingeben und wählen.
- Typ "Handschriftlich" wählen.
- Das Jahrhundert kann man auch eingrenzen.
- "Wörter" heißt wie viele Wörter wurden zum Erstellen des Modells verwendet. Je mehr desto besser.
- "CER" heißt Character Error Rate (Zeichenfehlerrate) also wie viel Prozent der Wörter wurden falsch erkannt. Je weniger desto besser.
- Die Beschreibung des Modells kann man mit Klick auf "Beschreibung" anschauen, z.B. "Transkribus German handwriting M1" inkludiert das Modell "Transkribus German Kurrent M2" plus Modelle mit lateinischer Schrift. Dieses Modell funktionierte sehr gut bei meinen bisherigen Tests.
- Man kann das Modell zu den Favoriten hinzufügen mit Klick auf den Stern.
- Ich habe keine Möglichkeit gesehen, im Nachhinein zu sehen, welches Modell man verwendet hat. Dies kann man z.B. unter den Metadaten selber vermerken.
- "Start>" klicken. Erst jetzt wird ein Credit verbraucht.
- "Jobs" klicken. Abwarten. Je komplizierter der Text ist bzw. wie viele andere Benutzer gerade damit arbeiten, kann es länger dauern.
- Wenn fertig, unter "Action" den Link klicken, dann auf der Miniaturansicht klicken.
- Jetzt ist man im Textbearbeitungsmodus. Man kann Wort für Wort den Text prüfen und ändern.
- Beim Klick auf eine Stelle im Bild hüpft der Kursor zur gleichen Stelle im Text und umgekehrt.
- Ganz links unten ist ein Button für den Vollbildmodus.
- Mit dem 3. Button von rechts ganz unten ("Ansicht wechseln") kann man zwischen nebeneinander und untereinander schalten.
- Bild und Text kann man getrennt voneinander vergrößern und verkleinern.
- Unter dem "Konfiguration"-Symbol ganz unten rechts eventuell "Automatically center line" ausschalten.
- Wenn man ein Wort im Text markiert kann man den Text formatieren (fett, schräg, unterstrichen usw.) bzw. mit Tags versehen.
- Mit Tags kann man unsichere Transkriptionen, Abkürzungen usw. markieren. Bei ungewöhnlichen Begriffen kann man den häufigeren Begriff als Kommentar hinzufügen.
- Den Status des ganzen Textes z.B. als "In Bearbeitung" oder "Erledigt" markieren. Achtung: Status "Trainigsdaten" (eigentlich "Trainingsdaten", englisch "Ground Truth") soll nur gesetzt werden wenn man alle Struktur- und Textänderungen 100% fertig hat! Somit lernt das Modell für weitere Transkriptionen anhand der eigenen Korrekturen.
- Unter dem Download-Symbol kann man das Bild zusammen mit dem Text exportieren, dazu gibt es mehrere Optionen. Sonst kann man einfach den Text markieren, kopieren und woanders einfügen. Allerdings werden die Zeilennummern mitkopiert. Also vorher unter dem "Konfiguration"-Symbol die Option "Show line and region number" ausschalten.
- Man kann unter den hinaufgeladenen Texten nach Begriffen suchen.
- Training (eigene Modelle erstellen oder zu bestehenden Modellen beitragen/verbessern). Aufwändig, mindestens 20 Seiten erkennen.
- https://transkribus.ai/ - Schnell und einfach, dafür weniger Kontrolle und keine Textverarbeitung. Keine Credits werden verbraucht, da man sich nicht anmeldet. Exportieren als PDF oder Word Doc (jeweils mit Bild und Text) oder Zwischenablage (nur Text).
Fazit:
Transkribus ersetzt keinesfalls Kenntnisse in Kurrent, kann aber die Arbeit damit erleichtern, abhängig von der Art des Textes.
- Weitere Hilfe zu Transkribus: https://readcoop.eu/de/transkribus/ressourcen/
- YouTube-Kanal von Transkribus: https://www.youtube.com/@transkribus
- Facebook-Seite von Transkribus: https://www.facebook.com/search/top?q=transkribus%20platform
- Facebook-Seite von Transkribus-Anwendern: https://www.facebook.com/groups/614090738935143
- Ein guter Erfahrungsbericht von Transkribus: https://archivalia.hypotheses.org/124394
Und wenn man alles endlich transkribiert hat, hat man noch immer einen Text z.B. aus dem 18. Jahrhundert, der wegen ungewohnten Vokabeln und Formulierungen schwer zu verstehen ist. Was macht man? Man nimmt ein weiteres KI-Werkzeug, nämlich ChatGPT.
Websites für Online-OCR
- https://www.onlineocr.net/ - Ausgabemöglichkeit als XLS, eine der wenigen Websites, die ich kenne, die das können. Ich habe z.B. den maschinengeschriebenen Geburtenindex Erdberg 1891-1910 damit gemacht (21.420 Zeilen, über 800 Seiten).
- https://online2pdf.com/convert-scanned-pdf-to-searchable-pdf - Suchbare PDF-Dateien erstellen.
toll gemacht,...
AntwortenLöschenDanke!
Löschen